Getting started with reading Deep Learning research papers: the Why and the How
With hundreds of papers being published every month, anybody who is serious about learning in this field cannot rely merely on tutorial-style articles or courses where someone else breaks down the latest research for him/her.


How do you continue the learning after you have consumed that book or completed that amazing online course on Deep Learning? How do you become “self-sufficient” so that you don’t have to rely on someone else to break down the latest breakthrough in the field?
— You read research papers.

A short note before you start — I am no expert at Deep Learning. I have only recently started reading research papers. In this article, I am going to write about everything that I found helpful when I started.
The WHY
In the answer to a question on Quora, asking how to test if one is qualified to pursue a career in Machine Learning, Andrew Ng (founder Google Brain, former head of Baidu AI group) said that anyone is qualified for a career in Machine Learning. He said that after you have completed some ML related courses, “to go even further, read research papers. Even better, try to replicate the results in the research papers.”
Dario Amodei (researcher at OpenAI) says that, “To test your fit for working in AI safety or ML, just trying implementing lots of models very quickly. Find an ML model from a recent paper, implement it, try to get it to work quickly.”
This suggests that reading research papers is crucial to further one’s understanding of the field.
With hundreds of papers being published every month, anybody who is serious about learning in this field cannot rely merely on tutorial-style articles or courses where someone else breaks down the latest research for him/her. New, ground-breaking research is being done as you read this article. The pace of research in the field has never been higher. The only way you can hope to keep up with the pace is by making a habit to read research papers as they are released.
In this article, I will try to give you some actionable advice on how you can start reading a paper yourself. Then, in the end, I will try to break down an actual paper so you may get started.
The HOW
First things first, reading a scientific research paper is difficult. In fact—
“Nothing makes you feel stupid quite like reading a scientific journal article.”

I just wanted to put that first so you don’t get discouraged if you feel like you can’t really understand the contents of a paper. It is unlikely that you understand it in the first few passes. So, just be gritty and take another shot at it!
Now, let us talk about a few valuable resources that will help you in your reading journey..
arXiv.org
Think of it as this place on the internet where researchers publish their papers before they are actually published in the those reputable scientific journals or conferences (if ever).
Why would they do that?
Well, it turns out that doing the research and actually writing the paper is not the end of it (!). Getting a paper from being submitted to being published in some scientific journal is quite a long process. After a paper is submitted to one of these journals, there’s a peer review process which can be quite slow (sometimes even spanning multiple years!) Now, this is really undesirable for a fast moving field like Machine Learning.
That’s why, arXiv.
Researchers publish their papers on a pre-print repositories like arXiv to quickly disseminate their research and get quick feedbacks on it.
Arxiv Sanity Preserver
Okay, so allowing researchers to easily pre-print their research papers is good. But what about the people reading those papers? If you go to the arXiv website, it is easy to feel scared and small and lost. Definitely not a place for newcomers ( just my opinion, you are welcome to try it though ☺ ).
Enter, Arxiv Sanity Preserver.
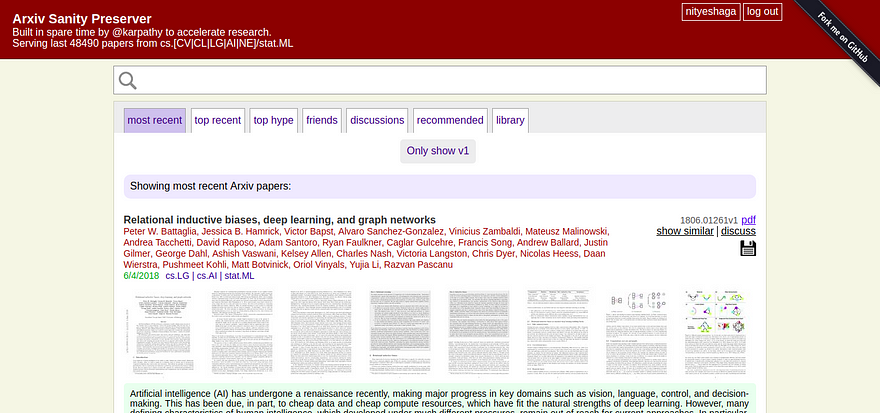
Arxiv Sanity does to arXiv, what Twitter’s newsfeed does to Twitter (except that it is totally open-sourced and free of advertising, obviously). Just as the newsfeed lets you see the most interesting tweets, personalised to your own taste, from amongst the large large sea that is Twitter, similarly Arxiv Sanity brings to you the papers on ML, published on arXiv, that might be the most interesting for you. It lets you sort the papers based on what’s trending, based on your past likes and the likes of the people that you follow. (Just those personalised recommendations features that we have got so used to over the social media, you know.)
Machine Learning- WAYR thread on Reddit
WAYR is short for What Are You Reading. Its a thread on the subreddit Machine Learning where people post the ML papers that they have read in this current week and discuss what they found interesting in it.
As I said, the number of research papers being published in the field of Machine Learning every week on arXiv is extremely large. This means that it is nearly impossible for a person to read all of them, every week and do regular things like attending college or going to a job or well, interacting with other human beings. Also, its not like all the papers are even worth reading.
Hence, you need to devote your energy to reading only the most promising papers and the thread that I mentioned above is one way of doing so.
Newsletters, Newsletters, Newsletters!
Newsletters are my personal best source of keeping up with the latest advances in the field of AI. You can simply subscribe to them and have them delivered to your inbox every Monday for free! And just like that, you can get to know about the most interesting news, articles and research papers of the week related to AI.
Here are the ones that I have subscribed to:
- Import AI by Jack Clark
This is my favourite because in addition to giving information about everything that I mentioned above, it also features a section called “Tech Tales”. This section contains a new AI- related short sci-fi story based on past week’s events!
(Psst.. a confession: Even on those weeks when I don’t feel so enthusiastic about new things in AI, I will skim though this newsletter just because of the Tech Tales) - Machine Learnings by Sam DeBrule
He also maintains a medium publication by the same name. It contains some really interesting articles. Be sure to check them out too. - Nathan.ai by Nathan Benaich
While the above two newsletters are weekly, this is a quarterly newsletter. So, you get one long email every 3 months which summarises the most interesting developments in the field for the past 3 months. - The Wild Week in AI by Denny Britz
I really liked this one because how its clean, concise presentation but it seems like this has become inactive since the past 2 months. Anyway, I am mentioning it here just in case Denny starts sending those emails again.
“AI people” on Twitter
Another good way by which you could keep up with the best and the latest in the field is by following the famous researchers and developers accounts on Twitter. Here’s a list of people that I follow:
- Michael Nielsen
- Andrej Karpathy
- Francois Chollet
- Yann LeCun
- Chris Olah
- Jack Clark
- Ian Goodfellow
- Jeff Dean
- OpenAI (I know this is not “people” but yeah..)
“That’s all good, but how do I start??”
Yes, that is the more pressing concern.
Okay so, first of all make sure that you understand the basics of Machine Learning like regression and other such algorithms, the basics of Deep Learning — plain vanilla neural networks, backpropagation, regularisation and a little more than the basics like how ConvNets, RNN and LSTM work. I really don’t think that reading research papers is the best way to clear your basics on these topics. There are plenty of other resources that you can refer to for doing so.
Once you have done that, you should start by reading a paper that originally introduced one of those above ideas. This way, you will be able to focus on just getting used to how a research paper looks. You won’t have to worry too much about actually understanding your first research papers since you are already quite familiar with the idea.
I recommend that you start with the AlexNet paper.
Why this paper?
Look at this graph:
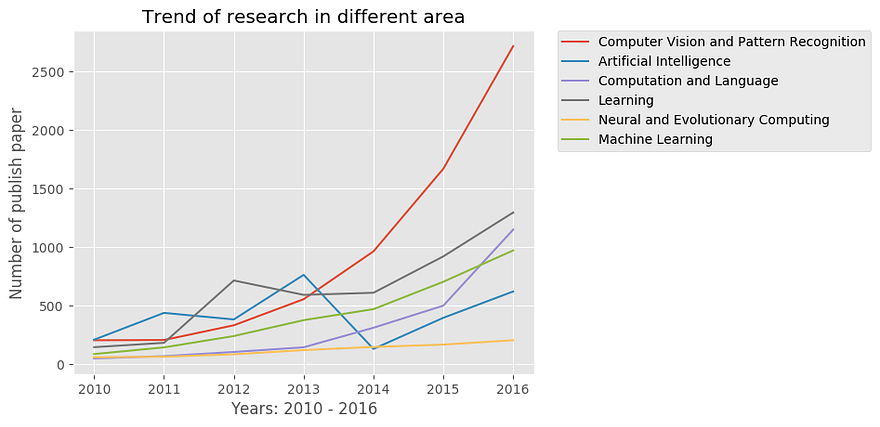
See how the Computer Vision and Patter Recognition curve just shoots up in the year 2012? Well, that’s largely because of this paper.
!!!
This is the paper that rekindled all the interest in Deep Learning.
Authored by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, and titled ImageNet Classification with Deep Convolutional Networks, this paper is regarded as one of the most influential papers in the field. It describes how the authors used a CNN (named AlexNet) to win the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 2012.
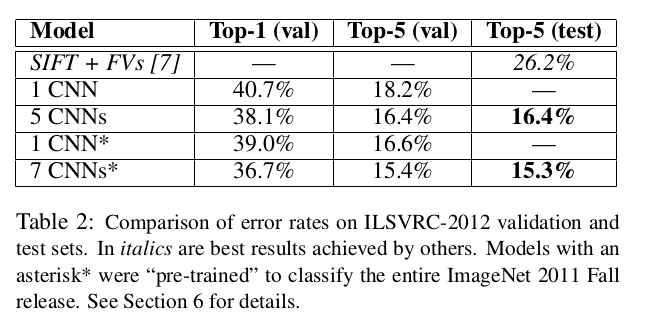
For those of you who don’t know, enabling computers to see and identify objects (aka Computer Vision) is one of the earliest goals of Computer Science. ILSVRC is like the Olympics for such “seeing computers” in which the participants (computer algorithms) try to correctly identify images as belonging to one of the 1000 categories. And, in 2012 AlexNet was able to win this challenge by a huge HUGE margin:
It achieved a top 5 error rate of 15.3% compared to the 26.2% that the second best entry recieved!
Needless to say, the entire Computer Vision community was awestruck and research in the area accelerated like never before. People started realising the power of Deep Neural Networks and well, here you are trying to understand how you can get a piece of the pie!
That being said, if you have a basic understanding of CNNs through some course or tutorial, it will be quite easy to grasp the contents of this paper. So, more power to you!
Once you are done with this paper, you may check out other such seminal papers relating to CNN or maybe move to some other architecture that interests you (RNNs, LSTMs, GANs).
There are also lots of repositories that have a good collection of important research papers in Deep Learning on Github (here’s a cool one). Be sure to check them out when you are starting. They will help you in creating your own reading list.
It would be highly remiss of me to not mention this one other source
- Distill.pub :
I have just one thing to say about it —
If all research papers were published in the Distill journal, then probably, I wouldn’t be writing this article, you wouldn’t have to read an article to guide you to reading a research paper and the internet would need much fewer (if at all) courses and tutorials that try to explain those seminal research ideas in comprehensible terms.
 Michael Nielsen
Michael Nielsen
So, be sure to check out the articles in there. It is really the next generation stuff!
Thank you for reading all the way through! I hope this article helps you in the task of keep up with the latest ML research. And remember, reading a scientific paper is difficult. So, there is no need to get discouraged. Just power through another reading if you don’t understand it.
Let me know your thought in the comments section below. You can also reach out to me on Twitter or LinkedIn.
I am a freelance writer. You can hire me to write similar indepth, passionate articles explaining an ML/DL technology for your company’s blog. Shoot me an email at nityeshagarwal[at]gmail[dot]com to discuss our collaboration.
Also, you can follow me on Twitter; I won’t spam your feed ;-)