"WTH does a neural network even learn?" - A newcomer's dilemma
It almost eases the mind to believe that we have this intangible sort of.. man-made “thing” that is analogous to the mind itself! It is especially appealing to someone who has just begun his/her Deep Learning journey.



I believe, we all have that psychologist/philosopher in our brains that likes to ponder upon how thinking happens.
“Deep networks have a hierarchical structure which makes them particularly well adapted to learn the hierarchies of knowledge that seem to be useful in solving real-world problems. Put more concretely, when attacking problems such as image recognition, it helps to use a system that understands not just individual pixels, but also increasingly more complex concepts: from edges to simple geometric shapes, all the way up through complex, multi-object scenes.”
- Michael Nielsen in his book Neural Networks and Deep Learning
There.
A simple, clear bird’s eye view of what neural networks learn — they learn “increasingly more complex concepts”.
Doesn’t that feel familiar? Isn’t that how we learn anything at all?
For instance, let’s consider how we, as kids, probably learnt to recognise objects and animals —
- We learn what ‘hands’, ‘legs’, ‘eyes’, ‘nose’, ‘mouth’ and ‘ear’ are.
- We learn to count and learn that we have 2 legs, hands, eyes and ears and only 1 nose and mouth.
- Then, we look at dogs and learn that a dog is like us, but with four legs instead of two, and no hands.
- Then we learn that an elephant is an animal, like a dog is, but huge and with a ridiculously long nose.
See?
So, neural networks learn like we do!
It almost eases the mind to believe that we have this intangible sort of.. man-made “thing” that is analogous to the mind itself! It is especially appealing to someone who has just begun his/her Deep Learning journey.
But NO. A neural network’s learning is NOT ANALOGOUS to our own. Almost all the credible guides and ‘starters packs’ on the subject of deep learning come with a warning, something along the lines of:
Disclaimer: Neural networks are only very loosely inspired by the brain. They do not represent the functioning of an actual human brain.
Caution: Any claims of them doing so, in front of a neurologist, may spark an intense battle of words.
..and that’s where all the confusion begins!
"Neural networks" are a sad misnomer. They're neither neural nor even networks. They're chains of differentiable, parameterized geometric functions, trained with gradient descent (with gradients obtained via the chain rule). A small set of highschool-level ideas put together
— François Chollet (@fchollet) January 12, 2018
The Confusion and why its even there
I think this was mostly because of the way in which most of the tutorials and beginner level books approach the subject.
Let’s see how Michael Nielsen describes what the hidden neurons are doing in his book — Neural Networks and Deep Learning:

He, like many others, uses the analogy between neural networks and the human mind to try to explain a neural networks. The way lines and edges make loops, which then help in recognising some digits is what we would think of doing. Many other tutorials try to use a similar analogy to explain what it means to build a hierarchy of knowledge.
I have to say that because of this analogy, I understand neural nets better.
But it is one of the paradoxes, that the very analogy that makes a difficult concept intelligible to the masses, can also create an illusion of knowledge among them.
Readers need to understand that it is just an analogy. Nothing more, nothing less. They need to understand that every simple analogy needs to be followed by more rigorous, seemingly difficult explanations.
Now don’t get me wrong. I am deeply thankful to Michael Nielsen for writing this book. It is one of the best books on the subject out there. He is careful in mentioning that this is “just for the sake of argument”.
But I took it to mean this —
Maybe, the network won’t use the same exact pieces. Maybe, it will figure out some other pieces and join them in some other way to recognise the digits. But the essence will be the same. Right? I mean each of those pieces has to be some kind of an edge or a line or some loopy structure. After all, it doesn’t seem like there are other possibilities if you want to build a hierarchical structure to solve the problem of recognising digits.
As I gained a better intuition about them and how they work, I understood that this view is obviously wrong. It hit me..
Even loops and edges don’t seem like a possibility for a NN!
Let’s consider loops —
Being able to identify a loop is essential for us humans to write digits- an 8 is two loops joined end-to-end, a 9 is loop with a tail under it and a 6 is loop with a tail up top. But when it comes to recognising digits in an image, features like loops seem difficult and infeasible for a neural network (Remember, I’m talking about your vanilla neutral networks or MLPs here).
- Apart from ‘0’ and ‘8’, a loop can only help in recognising a ‘6’ if it is in the lower half of the picture or it may help with a ‘9’ if it is in the upper half.
- So, if we have a simple network with a single hidden layer, we have already ‘used up’ 2 neurons of that layer, one for each position of the loop (upper/lower). This number is quickly multiplied when you consider the different shapes of the loops that are possible and the different spatial positions that these digits can be drawn at.
- Now, even a basic network architecture (vanilla NN) can achieve remarkable accuracies (>95%) with just 20–30 hidden neurons. So, you can understand why such a neural network might not be into loops that much.
I know its just a lot of “hand-wavy” reasoning but I think it is enough to convince. Probably, the edges and all the other hand-engineered features will face similar problems.
..and there’s the dilemma!
So, what features does a neural network ACTUALLY learn?
I had no clue about the answer or how to find it until 3blue1brown released a set of videos about neural networks. It was Grant Sanderson’s take at explaining the subject to newcomers. Maybe even he felt that there were some missing pieces in the explanation by other people and that he could address them in his tutorials.
And boy, did he!
The video
Grant Sanderson of 3blue1brown, who uses a structure with 2 hidden layers, says —
Originally, the way I motivated the structure was by describing a hope that we might have that the 2nd layer might pick up on little edges, the 3rd layer would piece together those edges to recognise loops and longer lines and that those might be pieced together [in the final layer] to recognise digits.
The very loops and edges that we ruled out above.
Is this what our network is actually doing?
Well for this one atleast — not at all!

Instead of picking up on isolated little edges here and there, they look.. well, almost random(!) just but some very loose patterns in the middle
They were not looking for loops or edges or anything even remotely close! They were looking for.. well something inexplicable.. some strange patterns that can be confused for random noise!
The Project
I found those weight matrix images (in the above screenshot) really fascinating. I thought of them as a Lego puzzle.

The weight matrix images were like the elementary Lego blocks and my task was to figure out a way to arrange them together so that I could create all 10 digits. This idea was inspired from the excerpt of Neural Networks and Deep Learning that I posted above. There we saw how we could assemble a 0 using hand-made features like edges and curves. So, I thought that, maybe, we could do the same with the features that the neural network actually found good.
All I needed was those weight matrix images that were used in 3blue1brown’s video. Now the problem was that Grant had put only 7 images in the video. So, I was gonna have to generate them on my own and create my very own set of Lego blocks!
Lego blocks, assemble!
I imported the code used in Michael Nielsen’s book to a Jupyter notebook. Then, I extended the Network class in there to include the methods that would help me visualise the weight matrices.
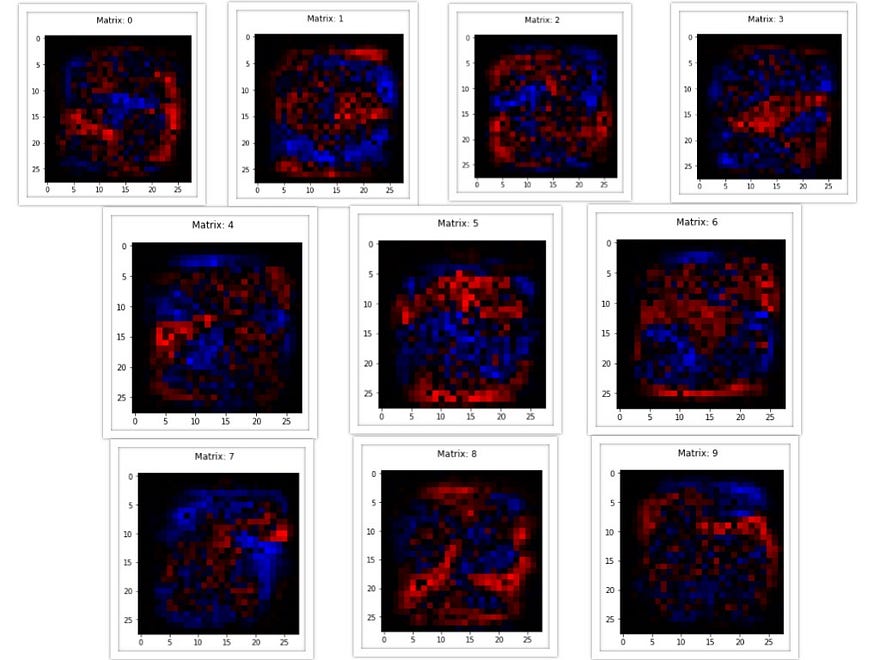
One pixel for every connection in the network. One image for each neuron showing how much it ‘likes’(colour: blue) or ‘dislikes’(colour: red) the previous layer neurons.
So, if I was to look at the image belonging to one of the neurons in the hidden layer, it would be like a heat map showing one feature, one basic Lego block that will be used to recognise digits. Blue pixels would represent connections that it “likes” whereas red ones would represent the connections that it “dislikes”.
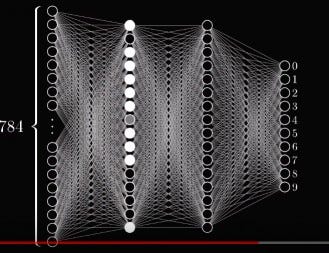
I trained a neural network that had:
- 1 Input layer (784 nodes)
- 1 Hidden layer (30 nodes)
- 1 Output layer (10 nodes)
Notice that we will have 30 different types of basic Lego blocks for our Lego puzzle here because that’s the size of our hidden layer.
And.. here’s what they look like! —
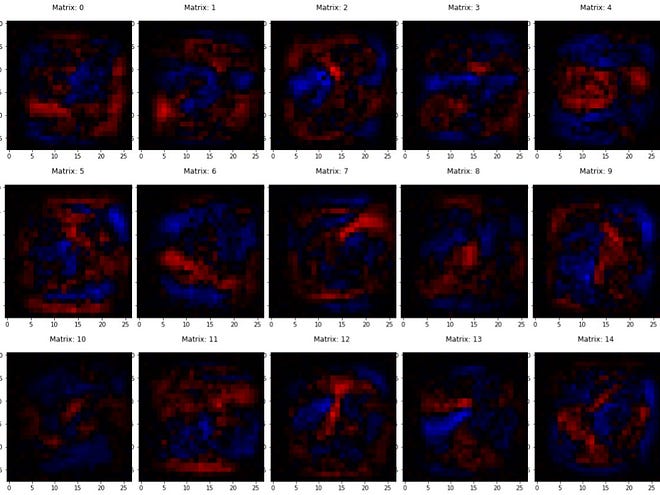
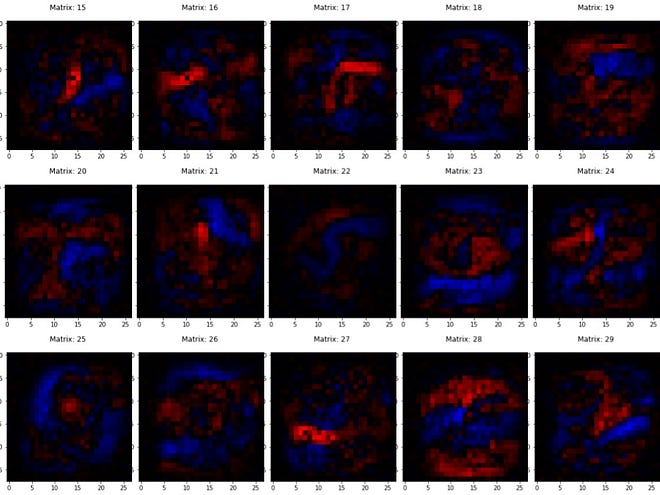
These are the features that we were looking for! The ones that are better than loops and edges according to the network.
And here’s how it classifies all 10 digits:
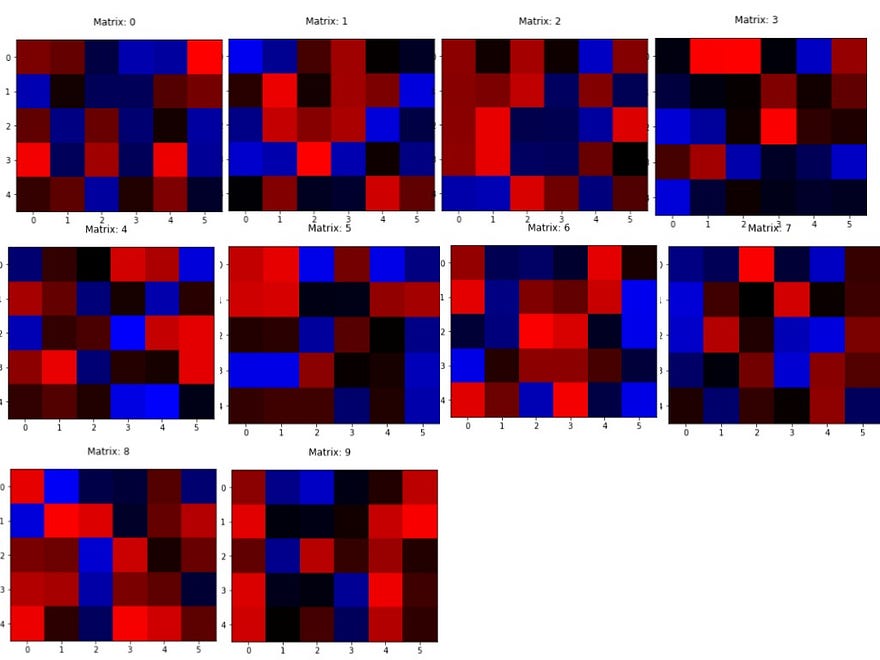
And guess what?
None of them make any sense!!
None of the features seem to capture any isolated distinguishable feature in the input image. All of them can be mistaken to be just randomly shaped blobs at randomly chosen places.
I mean, just look at how it identifies a ‘0':
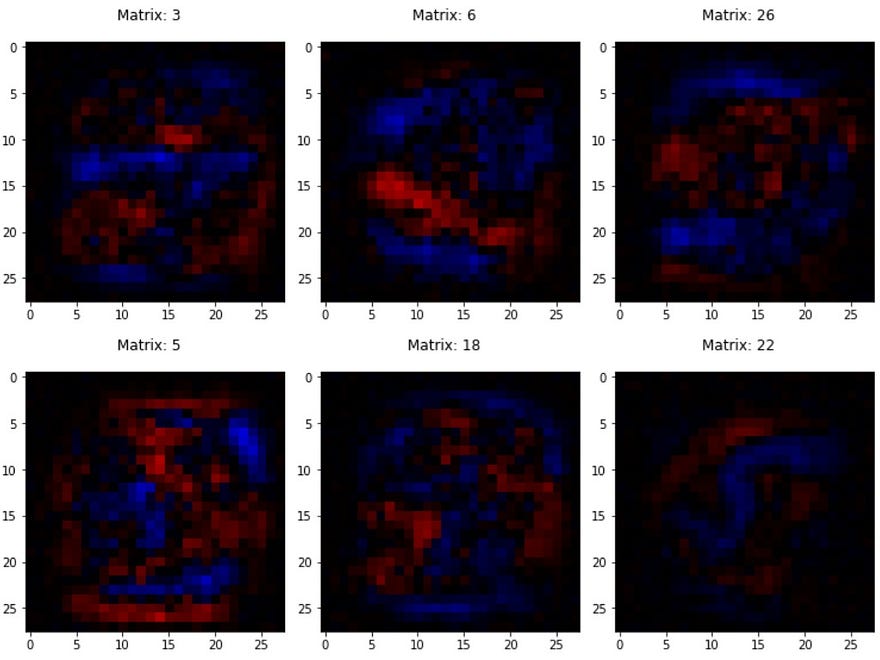
This is the weight matrix image for the output neuron that recognizes ‘0's:
To be clear, the pixels in this image represent the weights connecting the hidden layer to the output neuron that recognises ‘0's.
We shall take only a handful of the most useful features for each digit into account. To do that, we can visually select the most intense blue pixels and the most intense red pixels. Here, the blue ones should give us the most useful features and the red ones should give us the most dreaded ones (think of it as the neuron saying — “The image will absolutely *not* match this prototype if it is a 0”).
Indices of the three most intense blue pixels: 3, 6, 26
Indices of the three most intense red pixels: 5, 18, 22
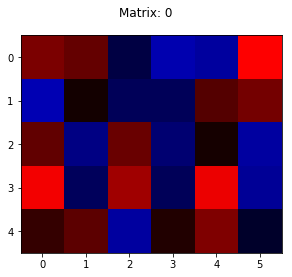
Matrices 6 and 26 seem to capture something like a blue boundary of sorts that is surrounding inner red pixels — exactly what could actually help in identifying a ‘0’.
But what about matrix 3? It does not capture any feature we can even explain in words. The same goes for matrix 18. Why would the neuron not like it? It seems quite similar to matrix 3. And let’s not even go into the weird blue ‘S’ in 22.
Nonsensical, see!
Let’s do it for ‘1’:
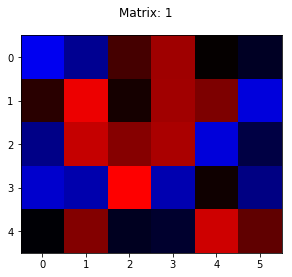
Indices of the three most intense blue pixels: 0, 11, 16
Indices of the top two most intense red pixels: 7, 20
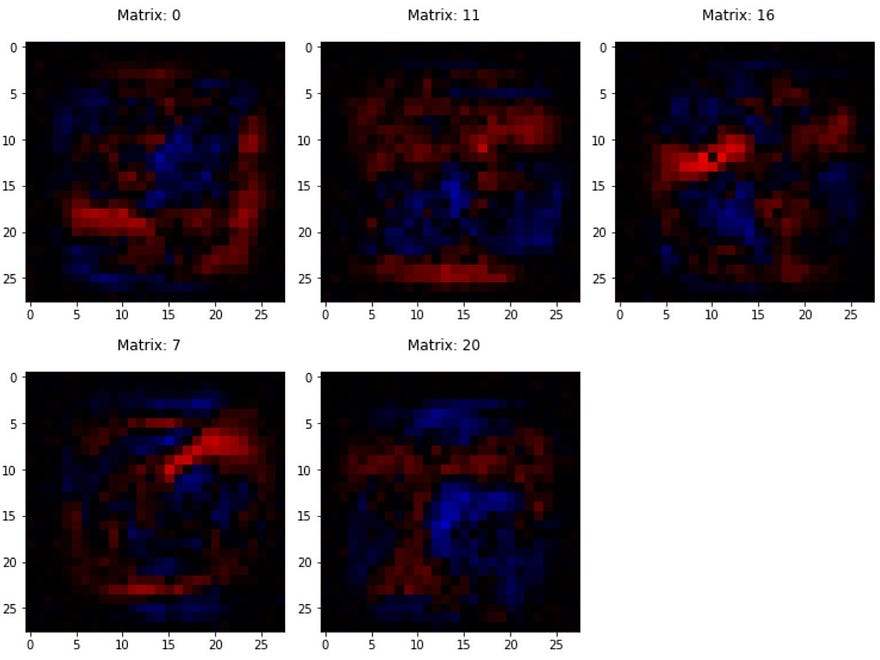
I have no words for this one! I won’t even try to comment.
In what world can THOSE be used to identify 1’s !?
Now, the much anticipated ‘8’ (how will it represent the 2 loops in it??):
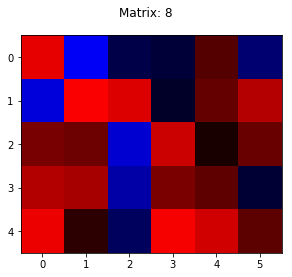
Top 3 most intense blue pixels: 1, 6, 14
Top 3 most intense red pixels: 7, 24, 27
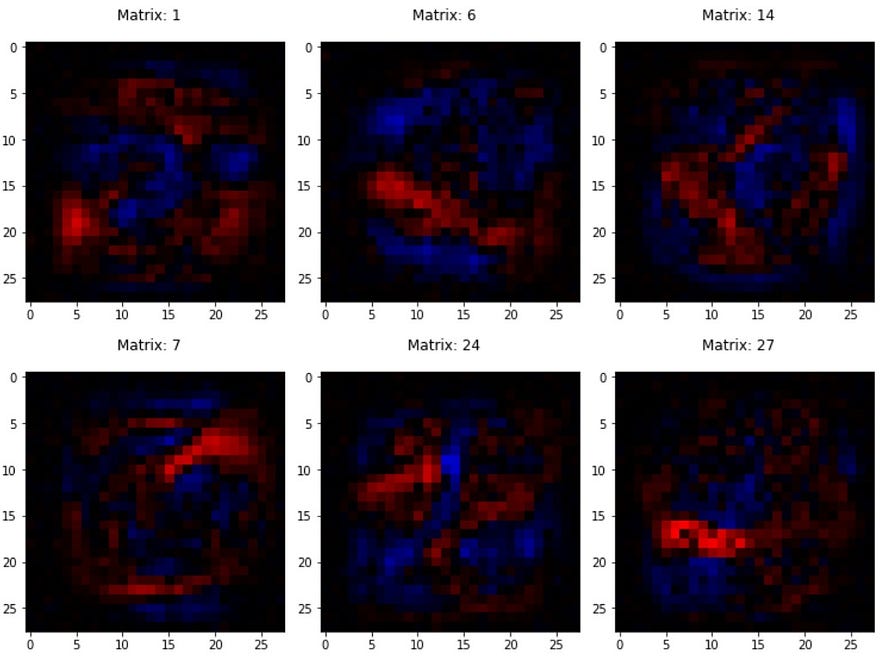
Nope, this isn’t any good either. There seem to be no loops like we were expecting it to have. But there is another interesting thing to notice in here — A majority of the pixels in the output layer neuron image (the one above the collage) are red. It seems like the network has figured out a way to recognise 8s using features that it does not like!
Inference
So, NO. I couldn’t put digits together using those features as Lego blocks. I failed real bad at the task.
But to be fair to myself, those features weren’t so much Lego-blocky either! Here’s why—
- They can be used in parts. What I mean is that their contribution status isn’t a 0 or 1. Some of those features are completely used, some are partially used, some are not and some have a negative (and yet an important!) effect upon the construction of a digit. This is unlike a Lego block which can either be used or not used.
- They don’t seem to capture any particular feature. Instead, they appear to be useful and logical only in combination with other hidden neurons (remember the debacle with matrix 3 and matrix 18 in recognising ‘0’?) . Some strange combination that the network has figured out using the immense calculus prowess that we gave it! A combination so incomprehensible that it just seems “almost random”!
So, there it is. Neural networks can be said to learn like us if you consider the way they build hierarchies of features just like we do. But when you see the features themselves, they are nothing like what we would use. The networks give you almost no explanation for the features that they learn.
Neural networks are good function approximators. When we build and train one, we mostly just care about its accuracy —
On what percentage of the test samples does it give positive results?
This works incredibly well for a lot of purposes because modern neural nets can have remarkably high accuracies — upward of 98% is not uncommon (meaning that the chances of failure are just 1 in a 100!)
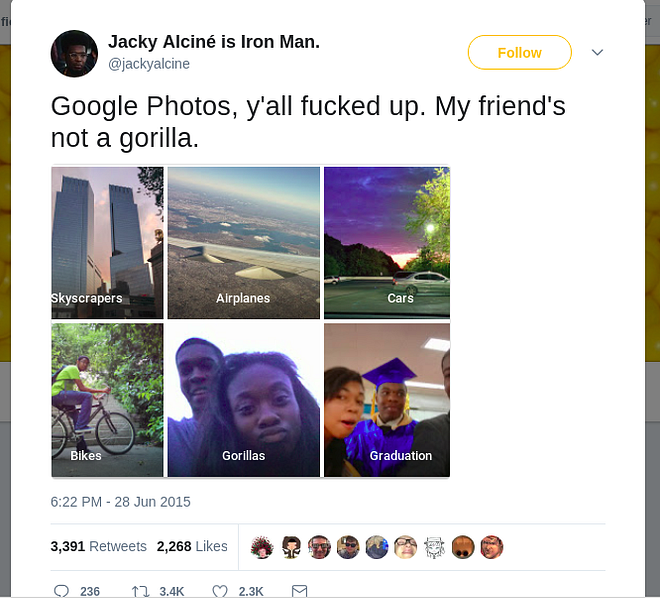
But here’s the catch — When they are wrong, there’s no easy way to understand the reason why they are. They can’t be “debugged” in the traditional sense. For example, here’s an embarrassing incident that happened with Google because of this:

Understanding what neural networks learn is a subject of great importance. It is crucial to unleashing the true power of deep learning. It will help us in
- creating debuggable end-to-end systems solely based on neural networks
- using such systems to broaden our grasp on a variety of topics and ultimately achieve the goal of using Artificial Intelligence to augment human intelligence
A few weeks ago The New York Times Magazine ran a story about how neural networks were trained to predict the death of cancer patients with a remarkable accuracy.
Here’s what the writer, an oncologist, said:
So what, exactly, did the algorithm “learn” about the process of dying? And what, in turn, can it teach oncologists? Here is the strange rub of such a deep learning system: It learns, but it cannot tell us why it has learned; it assigns probabilities, but it cannot easily express the reasoning behind the assignment. Like a child who learns to ride a bicycle by trial and error and, asked to articulate the rules that enable bicycle riding, simply shrugs her shoulders and sails away, the algorithm looks vacantly at us when we ask, “Why?” It is, like death, another black box.
The Dying Algorithm, article by an oncologist in The New York Times Magazine
I think I can strongly relate to this because of my little project. :-)
Bonus section (feel free to skip)
During the little project that I described earlier, I stumbled upon a few other results that I found really cool and worth sharing. So here they are —
Smaller networks:
I wanted to see how low I could make the hidden layer size while still getting a considerable accuracy across my test set. It turns out that with 10 neurons, the network was able to classify 9343 out of 10000 test images correctly. That’s 93.43% accuracy at classifying images that it has never seen with just 10 hidden neurons.
Just 10 different types of Lego blocks to recognise 10 digits!!
I find this incredibly fascinating.
Of course, these weights don’t make much sense either!

In case you are curious, I tried it with 5 neurons too and I got an accuracy of 86.65%; 4 neurons- accuracy 83.73%; below that it dropped very steeply — 3 neurons- 58.75%, 2 neurons- 22.80%.
Weight initialisation + regularisation makes a LOT of difference:
Just regularising your network and using good initialisations for the weights can have a huge effect on what your network learns.
Let me demonstrate.
I used the same network architecture, meaning same no. of layers and same no. of neurons in the layers. I then trained 2 Network objects- one without regularisation and using the same old np.random.randn() whereas in the other one I used regularisation along with np.random.randn()/sqrt(n). This is what I observed:
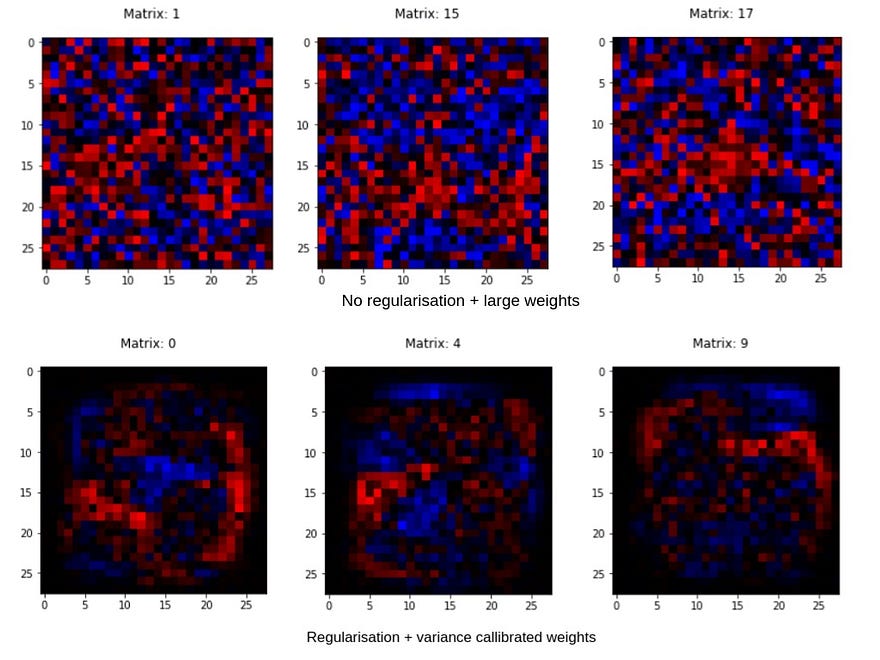
Yeah! I was shocked too!
(Note: I have shown the weight matrices associated with different index neurons in the above collage. This is because due to different initialisations, even the ones at the same index learn different features. So, I chose the ones that appear to make the effect most starking.)
To know more about weight initialisation techniques in neural networks I recommend that you start here.
Thank you for reading! 😄
If you want to discuss this article or any other project that you have in mind or really anything AI please feel free to comment below or drop me a message on LinkedIn or Twitter.
I am a freelance writer. You can hire me to write similar indepth, passionate articles explaining an ML/DL technology for your company’s blog. Shoot me an email at nityeshagarwal[at]gmail[dot]com to discuss our collaboration.
Also, you can follow me on Twitter; I won’t spam your feed ;-)