Use Kaggle to start (and guide) your ML and Data Science journey - Why and How
Earlier, I wasn’t so sure. I would say something like do this course or read this tutorial or learn Python first (just the things that I did). But now, as I am going deeper and deeper into the field, I am beginning to realise the drawbacks of the approach that I took.

I often get asked by my friends and college-mates — “How to start Machine Learning or Data Science”.
When you’ve written the same code 3 times, write a function
— David Robinson (@drob) November 9, 2017
When you’ve given the same in-person advice 3 times, write a blog post
So, here goes my answer..
Earlier, I wasn’t so sure. I would say something like do this course or read this tutorial or learn Python first (just the things that I did). But now, as I am going deeper and deeper into the field, I am beginning to realise the drawbacks of the approach that I took.
So, in hindsight, I believe that the best way to “get into" ML or Data Science might be through Kaggle.
In this article, I will tell you why I think so and how you can do that if you are convinced by my reasoning.
(Caution: I am a student. I am not a Data Scientist or an ML engineer by profession. I am definitely not an expert at Kaggle. So, take my advice/opinions with a healthy grain of salt. :-) )
But first, let me introduce Kaggle and clear some misconceptions about it.
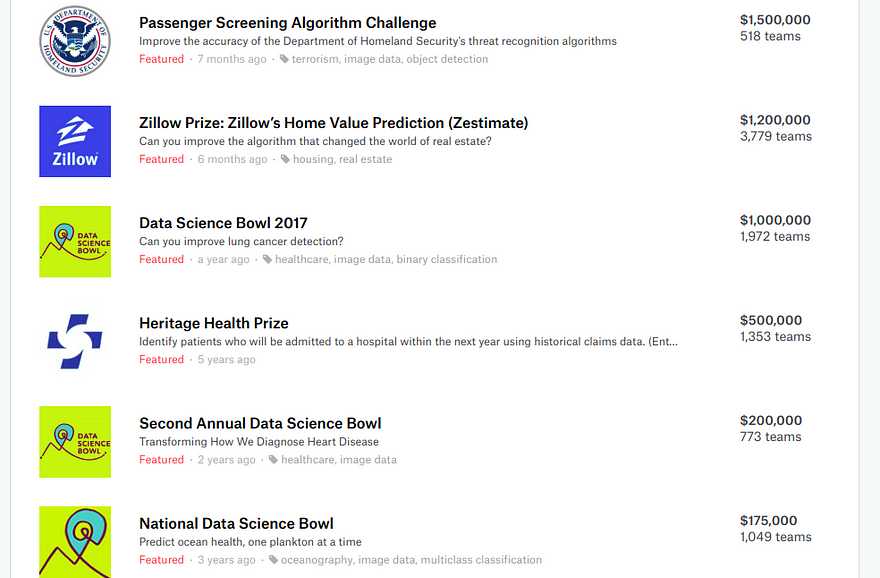
You might have heard of Kaggle as a website that awards mind-boggling cash prizes for ML competitions.
It is this very fame which also causes a lot of misconceptions about the platform and makes newcomers feel a lot more hesitant to start than they should be.
(Oh and don’t worry if you have never heard of Kaggle before and therefore, don’t share any of the below mentioned misconceptions. This article will still make complete sense. Just treat the next section as me introducing Kaggle to you.)
The misconceptions:
- “Kaggle is a website that hosts Machine Learning competitions”
This is such an incomplete description of what Kaggle is! I believe that competitions (and their highly lucrative cash prizes) are not even the true gems of Kaggle. Take a look at their website’s header—

Along with hosting Competitions (it has hosted about 300 of them now), Kaggle also hosts these 3 very important things:
Datasets, even the ones not related to any competition: It houses 9500 + datasets as compared to just the 300 competitions (at the time of writing). So you can sharpen your skills by choosing whatever dataset amuses or interests you.
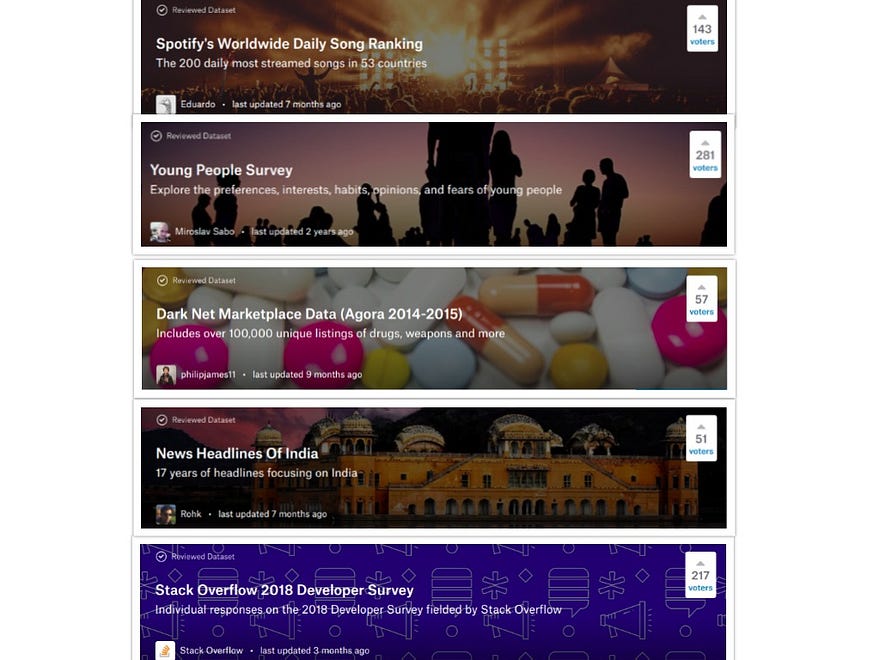
Kernels:They are just Kaggle’s version of Jupyter notebooks, which in turn, are just a really effective and cool way of sharing code along with lots of visualisations, outputs and explanations. The “Kernels” tab takes you to a list of public kernels which people use to showcase some new tool or share their expertise or insights about some particular dataset(/s).Learn: This tab contains free, practical, hands-on courses that cover the minimum prerequisites needed to quickly get started in the field. The best thing about them? — everything is done using Kaggle’s kernels (described above). This means that you can interact and learn.. no more passive reading through hours of learning material!

All of these together have made Kaggle much more than simply a website that hosts competitions. It has, now, also become a complete project-based learning environment for data science. I will talk about that aspect of Kaggle in details after this section.
2. “Only experts (PhD or experienced ML practitioner with years of experience) take part in and win Kaggle competitions”
If you think so, I urge you to read this —
 Pete Pachal
Pete Pachal
TL;DR: a high school kid became a Kaggle Competitions Master simply (or not-so-simply, perhaps?) by following his curiosity and diving into the competitions. In his own words,
“I don’t know all the math behind the algorithms, but in terms of actually using it, I think it’s much more important to have a logical understanding of how it works.”
3. “I should do a few more courses and learn advanced Machine Learning concepts before participating in Kaggle competitions, so that I have a better chance of winning”
The most important part of machine learning is Exploratory Data Analysis (or EDA) and feature engineering and not model fitting. In fact, many Kaggle masters believe that newcomers move to the complex models too soon when the truth is that simple models can get you very far.
As Albert Einstein said —
“Any intelligent fool can make things bigger and more complex. It takes a touch of genius — and a lot of courage — to move in the opposite direction.”
Besides, a lot of challenges have structured data, meaning that all the data exists in neat rows and columns. There is no complex text or image data. So, simple algorithms (no fancy neural nets) are often the winning algorithms for such datasets. EDA is probably what differentiates a winning solution from others in such cases.
Now, let’s move on to why you should use Kaggle to get started with ML or Data Science..
Why should you get started with Kaggle?
Reason #1 — Learn exactly what is essential to get started
The Machine Learning course on Kaggle Learn won’t teach you the theory and the mathematics behind ML algorithms. Instead, it focuses on teaching only those things that are absolutely necessary in analysing and modelling a dataset. Similarly, the Python course over there won’t make you an expert at Python but it will ensure that you know just enough to go to the next level.
This minimises the time that you need to spend in passive learning and makes sure that you are ready to take on interesting challenges ASAP.
Reason #2 — Embodies the spirit of Building To Learn
I believe that doing projects is so effective that its worth centering your entire learning around completing one. What I mean to say is that instead of searching for a relevant project after you learn something, it might be better to start with a project and learn everything you need to to bring that project to life.
As Whitney Johnson said in a Masters of Scale podcast,
“Basically, you, me, everyone, we want to learn and leap and then repeat.”
I believe that learning is more exciting and effective this way.
(I wrote an article about the above methodology a few weeks ago. Its called — “How (and why) to start building useful, real-world software with no experience”. So, check that out if you haven’t :-) )
It took me a while to really admit to myself that just reading a book is not learning but entertainment.
— Andrej Karpathy (@karpathy) July 15, 2018
But this idea totally fails when you don’t have a project to leap towards. And doing an interesting project is difficult because..
a) ..it is difficult to find an interesting idea
And finding ideas for Data Science projects seems to be even more difficult because of the added requirement of having suitable datasets.
b) ..I don’t know what to do about those gaping holes in my knowledge
Sometimes when I have started some project, it feels like there are just so many things that I still don’t know. I feel like I don’t even know the prerequisites for learning the prerequisites to build this thing. Am I just out of my depth? How do I go about learning what I don’t know?
And that’s when all the motivation starts to wane away.
c) ..I am just “stuck” more often than not
It seems like I keep hitting one roadblock after the other during the building process. It would be so good if I could have a group of people and know how they would tackle the problem.
And here’s how Kaggle is able to provide a solution to all of these problems —
Soln. a → Datasets and Competitions :
With around 300 competition challenges, all accompanied by their public datasets, and 9500+ datasets in total (and more being added constantly) this place is like a treasure trove of Data Science/ ML project ideas.
Soln. b → Kernels and Learn :
Let me tell you how Kernels are helpful..
All the datasets have a public kernels tab where people can post their analysis for the benefit of the entire community. So, anytime you feel like you don’t know what to do next, you can be sure to get some ideas by looking at those kernels. Besides, a lot of those kernels are written especially to help the beginners.
Soln. c → Kernels and Discussion :
Along with the public Kernels that I just described above, each competition and each dataset also has its own Discussion forum. So, you always have a place to ask questions.
Apart from that, “during the competitions, many participants write interesting questions which highlight features and quirks in the data set, and some participants even publish well-performing benchmarks with code on the forums. After the competitions, it is common for the winners to share their winning solutions” (as written in the article, “Learning From the Best”)
Reason #3 — Real data to solve a Real problem => Real motivation
The challenges on Kaggle are hosted by real companies looking to solve a real problem that they encounter. The datasets that they provide are real. All that prize money is real. This means that you get to learn Data Science/ ML and practice your skills by solving real-world problems.
If you have tried competitive programming before, you might relate to me when I say that the problems hosted on such websites feel too unrealistic at times. I mean why should I try to write a program to find out the number of Pythagorean triplets in an array? What is that going to accomplish!?
I am not trying to assert that such problems are easy; I find them extremely difficult. Nor am I trying to undermine the importance of websites that host such problems; they are a good way to test and improve your data structures and algorithms knowledge.
All I’m saying is that it all feels way too fictional to me. When the problem that you are trying to solve is real, you will always want to work on improving your solution. That will provide the motivation to learn and grow. And that’s what you can get from participating in a Kaggle challenge.
The Other Side of the debate: “Machine Learning isn’t Kaggle competitions”
I will be remiss to not mention the other side of this debate which argues that Machine Learning isn’t Kaggle competitions and that Kaggle competitions only represent a “touristy sh*t” of actual Data Science work.
Well, maybe that is true. Maybe real data science work doesn’t resemble the approach one takes in Kaggle competitions. I haven’t work in a professional capacity, so I don’t know enough to comment.
But what I have done, plenty of times, is use tutorials and courses to learn something. And each of those times, I felt like there was a disconnect between the tutorial/course and my motivation to learn. I would learn something just because it is there in the tutorial/course and hope that it comes of use in some distant, mystical future.
On the other hand, when I’m doing a Kaggle challenge, I have an actual need to learn. I have a stage that allows me to immediately apply what I have learnt and see its effects. And that gives the motivation and the glue to make all that knowledge stick.
How you can get started:
Having all those ambitious, real problems has a downside that it can be an intimidating place for beginners to get in. I understand this feeling as I have recently started with Kaggle myself. But once I overcame that initial barrier, I was completely awed by its community and the learning opportunities that it has given me.
So, here I try to lay down how you can start:
Step 1. Cover the essential basics
Choose a language: Python or R.
Once you have done that, head over to Kaggle Learn to quickly understand the basics of that language, machine learning and data visualisation techniques.
Step 2. Find an interesting challenge/dataset
I would suggest that you choose a playground competition or one of the more popular competitions as you are starting out. This way you can be sure to find atleast some public kernels aimed at helping the newcomers.
Remember your goal isn’t to win a competition. It is to learn and improve your knowledge of Data Science / ML.
Step 3. Explore the public kernels
They will help you understand the general workflow of the field as well as the particular approach that other people are taking for this competition.
Often, these kernels will tell you what you don’t know in ML/ Data Science. Don’t feel discouraged when you encounter an unfamiliar term.
Knowing what you need to know is the first step to knowledge.
They are just the things that you need to learn to help you grow. But before you do that..
Step 4. Develop your own kernel
Go work on your own analysis. Build as much as you can with your current knowledge. Implement whatever you learnt from the previous steps in your own kernel.
Step 5. Learn what you need to and go back to step 4
Now, you do the learning. Sometimes, it is just a short article while at other times it can be a meaty tutorial/course. Just remember that you need to go back to step 3 and use what you learn in your kernel. This way you create the cycle needed to — “Learn, Leap and Repeat”!
Step 6. Improve your analysis by going back to step 3
You come to this step once you have built an entire prediction model. So, congratulations for that! 🎉
Now you probably want to improve your analysis. To do that you can go back to step 3 and look at what other people have done. That can give you ideas about improving your model. Or, if you feel like you have tried everything but have hit a wall, then asking for help on the discussion forums might help.
Great! Now go do more challenges, analyse more datasets, learn newer things!
Links to other resources
Learn Python:
Python has become super popular. This means that there are tonnes of excellent guides and tutorials that can help you get started with the language. These are the two resources that I used when I first learnt Python —
Obviously, these do not make a definitive list of resources to learn Python but these are the ones that worked best for me at the time when I started.
Machine Learning articles:
Before you deep dive into a field, you might want to know what it is all about. So, here are a few articles that give an interesting introduction to Machine Learning —
- “How to Learn Machine Learning, the self-starter way” by EliteDataScience
A well written article that does a great job at introducing Machine Learning and even lays out a self-study course! - “Machine Learning for Humans” by Vishal Maini
“This guide is intended to be accessible to anyone. Basic concepts in probability, statistics, programming, linear algebra, and calculus will be discussed, but it isn’t necessary to have prior knowledge of them to gain value from this series.” - “The Best Machine Learning Resources ” by Vishal Maini
This article is a part of the above mentioned series. I mention it separately because it has a very good, comprehensive set of links related to ML. - “Machine Learning is Fun” by Adam Geitgey
Read this series to know what is cool about ML. Although it is quite technical, it can serve as a great source of motivation to know more about the field.
Data Science blogs:
Here are a few good Data Science related blogs that you can check out —
Alright then. Thank you for reading. I hope this has been helpful for you.
One last thing about finding inspiration and motivation as you go on your new journey and do something awesome —
“Your influences are not necessarily the things that you think they are. Remember that your influences are all sorts of things and some of them are gonna take you by surprise but the most important thing that you can do is open yourself to everything.”
— Neil Gaiman in his MasterClass-the Art of Storytelling
Finding inspiration might be just as important as learning new Data Science/ML concepts, if not more. The Internet is filled with awesome stuff created by inspiring people from all walks of life. Make it a habit to follow them and read such stuff because that is what will drive you to do more, to learn more and be a better version of yourself.
9/ The tools for learning are abundant. It’s the desire to learn that’s scarce.
— Naval (@naval) September 25, 2017
It may be hard to find such content in this clickbaity, behaviour-driving social media age but trust me, it exists. And that it why, to help you navigate in this ocean better, I have started a free weekly email newsletter — Good Surfer. I write each newsletter with one goal in mind —
Teach the readers how to find motivating and insightful content over the Internet.
If you think Good Surfer would benefit you, I would love to have you as a subscriber!
Let me know your thought in the comments section below. You can also reach out to me on Twitter or LinkedIn.
I am a freelance writer. You can hire me to write similar indepth, passionate articles explaining an ML/DL technology for your company’s blog. Shoot me an email at nityeshagarwal[at]gmail[dot]com to discuss our collaboration.
Also, you can follow me on Twitter; I won’t spam your feed ;-)